Semi-Automated Alignment of Text Versions with iteal
A half-day tutorial at DH2018, CDMX, Mexico, June 2018
with
Stefan Jänicke @vizcovery
David Joseph Wrisley @djwrisley
Overview
Our half-day tutorial for DH2018 concerns the semi-automated alignment of different witnesses in complex textual traditions, with demonstration of specific use cases, a discussion of the relevance of the implemented system to particular textual problems relevant to the participants as well as a hands on discovery of the system. Alignment is a relatively simple task for modern languages with orthographic stability and relatively similar texts, but when there is a degree of instability of textual transmission as in oral literatures, popular music or poetry, or other complex texts with partial repetition the task becomes more difficult. Whereas methods of hand aligning and visualizing texts exists in TEI, we focus on the possibility of computational alignment for the purpose of exploratory textual visualization. Scholars who are interested in visualizing scaled forms of reading will be interested in this tutorial.
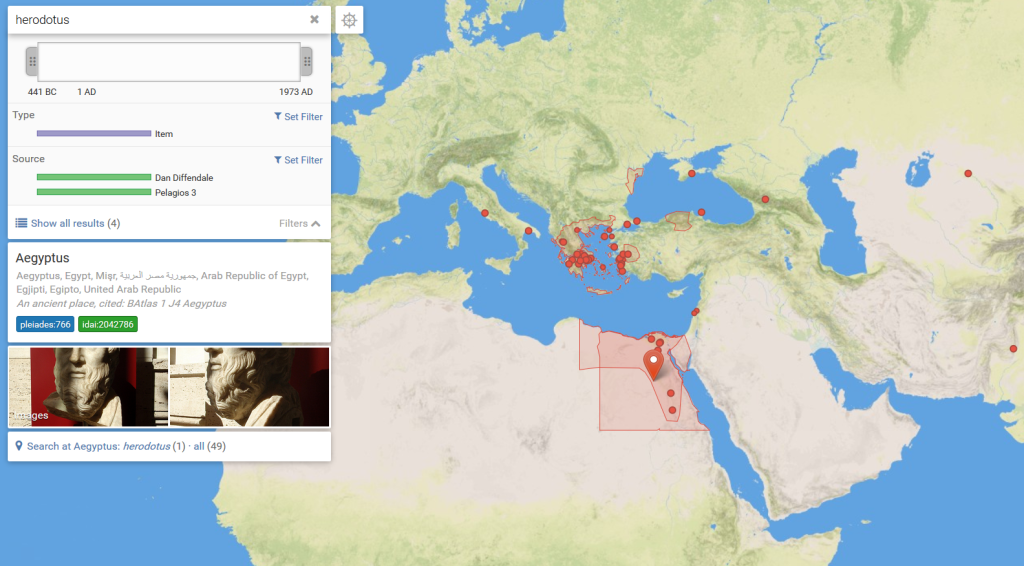
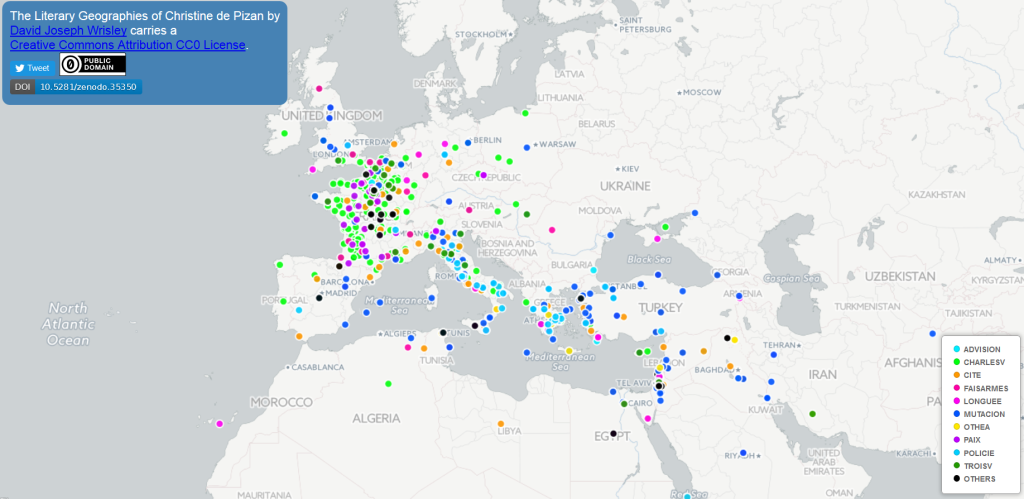
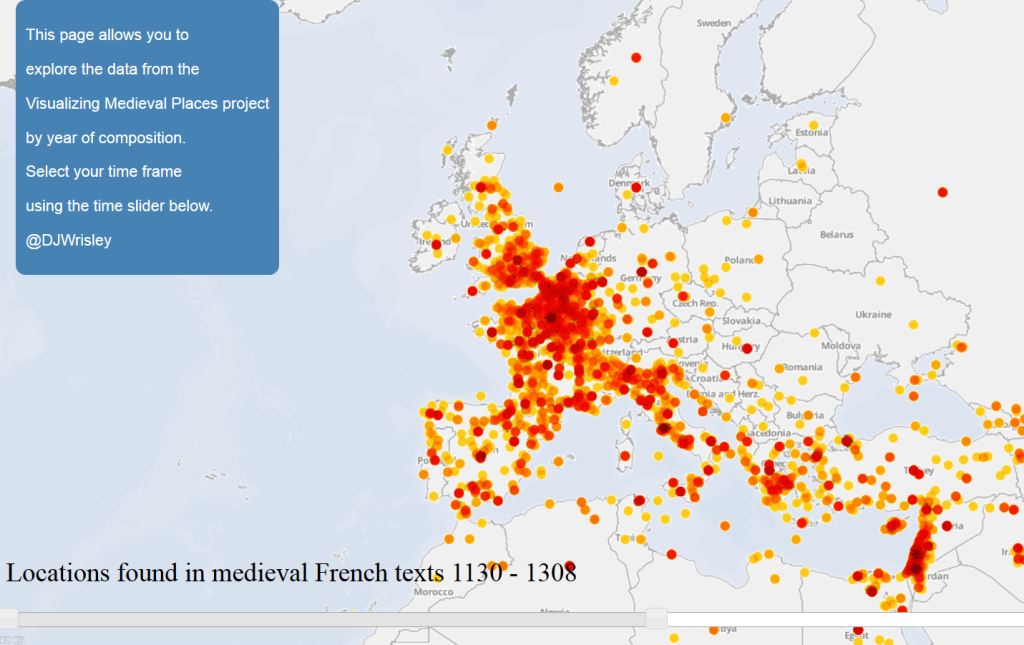
Our visual analytics environment iteal supports the computational alignment of textual similarities and is not English-specific. It was originally implemented using orally inflected medieval French poetic texts (with test cases of the fabliaux and epic) and so is known to work on texts in Latin alphabets with inconsistent orthography.
This half-day tutorial aims at introducing iteal to the DH community for which the questions of multi-text problems, spelling variance and debates about distant forms of reading are currently quite salient. Many language processing and visualization tools do not work well with languages beyond English. Our environment is known to work with languages beyond English will be of interest those interested in expanding innovative techniques in the textual humanities across the North/South divide. Participants of the tutorial will be led in a step-by-step, hands-on approach through the full cycle of an iteal-based text alignment workflow, and they will finally have the opportunity of testing the tool with their own data. Although proven to be effectively useful for text variants of medieval poetry, we will not focus only on this type of text as iteal can be used to determine alignments among texts of a different kind in any language and in multiple genres. Currently, iteal works with plain text in utf8.
iteal consists of two major modules:
First, it automatically determines line-to-line alignments pairwise between all given text editions based on user-configurable parameters including:
- Edit distance: Variant spellings are taken into account by this function. We define two words as spelling variants if they have the same first letter, and if the string similarity of the remaining substrings is higher than a user-configurable threshold.
- Coverage: In order to ensure that a specific proportion of words of both lines are aligned, the user can configure a minimum coverage value of the line.
- N-grams: The user can configure the minimum required n-gram size n that is the largest number of subsequent word matches of both lines.
- Broken n-grams: Quite often, the only difference between two lines is a single word in the middle of a line that is either inserted, synonymous, or a transposed stopword. Large n-grams, from this perspective are not achieved. Thus, we allow the user for considering broken n-grams, which is the total number of word matches among both lines.
Second, for the purpose of analyzing the determined alignment we provide interactive visualizations for different text hierarchy levels (examples for all three views can be found in Figures 1, 2 and 3, and a teaser outlining a brief workflow with iteal can be found at https://vimeo.com/230829975):
- Distant Reading: In order to get a rough overview of alignment patterns throughout the observed text versions, we draw a miniature representation for each version in the form of a vertical bar reflecting its number of verse lines in contrast to the other shown versions. For us, this is the most distant form of reading, where the text itself is not visualized, but rather abstract depictions of textual similarity point to patterns worth discovering.
- Meso Reading: Since multiple texts are displayed in synoptic views, the visualization is able to convey more complex patterns of textual relationship. We call this a meso reading that might be said to connect multiple close readings all the while transmitting information that lies beyond the scope of a close reading. Here, we use the intuitivity of stream graphs to connect aligned verse lines among different versions. For a more detailed inspection of an individual alignment, clicking on a stream opens a popup window for line-level close reading.
- Close Reading: Next to plain text, the close reading view provides word level alignments for the corresponding verse lines in the form of two Variant Graph visualizations. Within the close reading view, individual alignments can be confirmed with user input, so that it gets persistently stored in the backend.
Target audience: Anyone studying variance in the textual digital humanities and its visualization would be interested in our tutorial. It will be offered in English, but can accommodate textual data in a variety of languages. Potential participants in the tutorial are encouraged to be in touch with the presenters in advance of DH2018 to provide some sample data that can used to provide a mashup. Required for this step is a version of at least two documents sharing some text in common, of at least 20 lines.
Schedule #itealDH
Part I (1 hour + break time)
– iteal introduction: purpose, functionality, configuration, visualization (Stefan Jänicke)
– Medieval French poetry as an iteal use case (David J. Wrisley)
– Further use cases, future work, questions (Stefan Jänicke & David J. Wrisley)
Break
Part II (2 hours - break time)
– Step-by-step hands-on session with texts brought by tutorial participants
– wrap up, feedback and steps forward
Bios
Stefan Jänicke
Dr. Stefan Jänicke is a post-doctoral researcher at the Image and Signal Processing Group at Leipzig University, Germany, where he leads a text visualization group focusing on applications in the digital humanities. Over the last years, he has gained experience in developing information visualization and visual analytics techniques within a number of digital humanities projects. His PhD thesis investigates the utility of visualization techniques to support the comparative analysis of digital humanities data, and his current research relates to information visualization with a focus on applications for text- and geovisualization in digital humanities.
David Joseph Wrisley
Dr. David Joseph Wrisley is Associate Professor of Digital Humanities at New York University Abu Dhabi. His research interests include the creation of open, inclusive corpora in medieval studies, corpus-based geovisualization as well as visual exploration of variance in poetic traditions. Furthermore, he is interested in the challenges in humanities data stemming from both multilingual environments and social data creation.
Related References
Jänicke, A. Geßner, M. Büchler and G. Scheuermann (2014). Visualizations for Text Re-use. In: Proceedings of the 5th International Conference on Information Visualization Theory and Applications (VISIGRAPP 2014), pp 59–70.
Jänicke, A. Geßner, M. Büchler and G. Scheuermann (2014). 5 Design Rules for Visualizing Text Variant Graphs. In: Conference Abstracts of the Digital Humanities 2014.
Jänicke, A. Geßner, G. Franzini, M. Terras, S. Mahony and G. Scheuermann (2015). TRAViz: A Visualization for Variant Graphs. In: Digital Scholarship in the Humanities 30, suppl 1, pp i83–i99.
Jänicke, G. Franzini, M. F. Cheema and G. Scheuermann (2015). On Close and Distant Reading in Digital Humanities: A Survey and Future Challenges. In: Eurographics Conference on Visualization (EuroVis) - STARs. The Eurographics Association.
Jänicke and D. J. Wrisley (2017). Visualizing Mouvance: Towards a Visual Analysis of Variant Medieval Text Traditions. In: Digital Scholarship in the Humanities 32, suppl 2, pp ii106–ii123.